
Hive - A Fast and Powerful Data Warehouse Solution - Part 01
Hive functions like a Distributed Query Language unlike RDBMS


Brief
Hive is an open source data warehouse infrastructure built on top of Hadoop that allows you to query and analyze large datasets stored in distributed computer systems. Apache Hive is part of Hadoop Ecosystem acting as a powerful query engine on top of MapReduce. It uses SQL-like language (called HiveQL) to query Hadoop Distributed File System (HDFS).
It enables users to run queries against large datasets stored in Hadoop's distributed file system. Learning Hive is a great way to get familiar with SQL, Big Data, and Hadoop.
Originally named HCatalog, Hive was created by Facebook in 2008. In the early days at Facebook, Hive was used as a replacement for a MySQL database, albeit for less interactive use.
Features and Functions of Apache Hive
At the highest level, Hive acts as a data storage and retrieval system. It provides a SQL-like interface in a language called HiveQL. It acts like a SQL database, in a sense. It has a database name and database schemas.
Hive can read and write data in a variety of formats. Hive can join tables from different databases.
In fact, the only major feature that it doesn't have is user schema creation. The Hive file format is a binary file format. It is called ORC (object-relational-comparison) and packs a schema and data into a columnar format. It can be compressed to save space and decompressed while loading.
Hive is a data warehouse infrastructure built on top of Hadoop. It allows data to be queried using HiveQL, a SQL-like language.
The six main parts of Hive take you to the different relationships between RDBMS, Hive, and Server
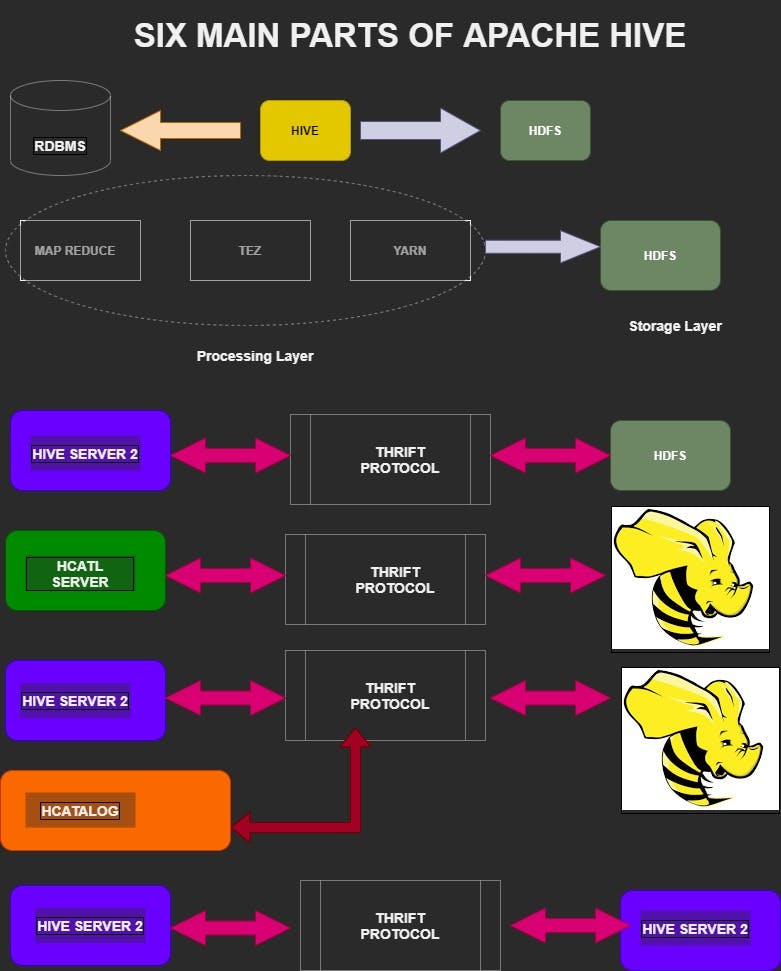
In subsequent parts of this article, we will dig deep into Hive and why it is important in Big Data Analytics field.